
ブログ/その他
中古2万円のGTX 1080 TiでローカルLLMは戦えるのか?VRAM 11GBの限界を検証
結論:遊べます。でもVRAM 11GBの壁にブチ当たる
先に結論。中古で安く手に入るGTX 1080 Ti(VRAM 11GB)でも、ローカルLLMは普通に動きます。
ただしモデルがデカくなるとVRAMを使い切って、生成の途中でサーバーごと落ちる。ここが最大の関門でした。
「とりあえずローカルAI試したいけど、最新のグラボに何万も出すのはキツい」って人向けの、リアルな人柱レポートです。
なぜ今さら1080 Tiなのか
理由はシンプルで、中古の値段に対してVRAMが11GBもあるから。
ローカルLLMで効くのは正直コア性能よりVRAM容量で、新しめのミドル帯でも8GBだったりする。そこに11GB積んでて秋葉原のハドフでジャンク品13200円。コスパだけ見ると今でもアリな選択肢でした。

結論は遊べる。でもVRAM 11GBの壁にブチ当たる
先に結論。中古で安く手に入るGTX 1080 Ti(VRAM 11GB)でも、ローカルLLMは普通に動きます。
ただしモデルがデカくなるとVRAMを使い切って、生成の途中でサーバーごと落ちる。ここが最大の関門でした。
「とりあえずローカルAI試したいけど、最新のグラボに何万も出すのはキツい」って人向けの、リアルな人柱レポートです。
なぜ今さら1080 Tiなのか
理由はシンプルで、中古の値段に対してVRAMが11GBもあるから。
ローカルLLMで効くのは正直コア性能よりVRAM容量で、新しめのミドル帯でも8GBだったりする。そこに11GB積んでて秋葉原のハドフでジャンク品13200円。コスパだけ見ると今でもアリな選択肢でした。
環境
- CPU:ryzen7 5700x
-RAM:24GB
- GPU:GTX 1080 Ti(VRAM 11GB)
- OS:Windows11
- 実行ツール:Ollama
- 試したモデル:gemma3 12b
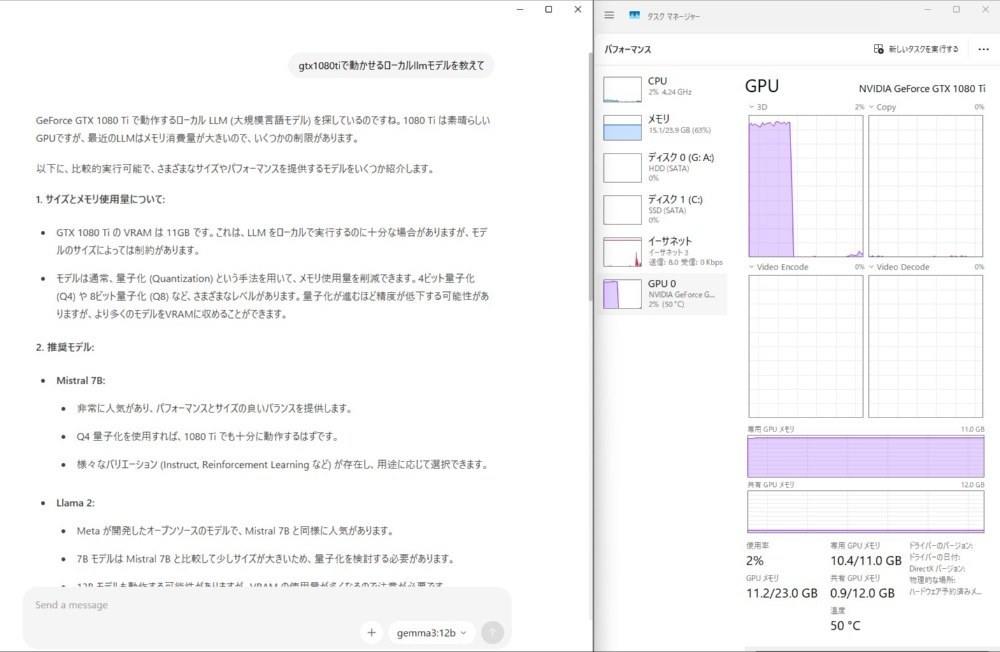
実際に動かしてみた → そして落ちた
軽量モデルは快適。Geminiくらい爆速。
問題は大きめのモデルを入れたとき。生成の途中でOllamaのサーバーが落ちる現象が発生しました。
最初は原因が分からなかったんですが、VRAM使用量を見たら11GBを使い切った瞬間に落ちてた。要するにVRAM不足です。
原因と対策
ここはまだ格闘中です
☆評価 ★★★☆☆コスパは◎、ただしVRAMの天井は低め。って感じでした。
質問あればコメントどうぞ。続編で別のグラボでも検証する予定です。
まとめ
結論:こんな人に向いてる
- - ローカルLLMをとにかく安く試したい人
- - 7〜9B級の軽量モデルで遊べれば満足な人
- - VRAMの壁と向き合う検証そのものを楽しめる人
- 逆に、デカいモデルをサクサク回したい人は素直に新しめのVRAM多めグラボへいってどうぞ。
評価
商品情報
- 製品名
- GTX1080Ti
- 購入価格
- ¥13,200
















私もAiエージェント構築をしているんですが、軽量モデルだとたまに会話が破綻したりするので快適に使用したい場合は、いいグラボがあったほうがいいですよね...
お金がなくてもLLMを触ってみたいという人にはありな選択肢だと思います!
なんでもないです